Neben meiner Erkältung habe ich von der Web2.0 Expo natürlich auch einiges an Infos mitgenommen. Ein bissl was davon kann ich nun prima in diesen Beitrag einbauen!
Eine schöne Aussage kam von Tom Coates in seinem Vortrag auf der Web 2.0 Expo “Designing for a web of data”:
turning from a web of pages to an aggregate web of connected data sources and services
Tja, nun sind wir also ständig damit beschäftigt, unsere Datenströme durch Web zu schieben und irgendwo einzufügen … was genauso nervig sein kann wie immer wieder die Freunde zu kontakten. Aber auch wie bei den Freunden gibt es auch schöne Beispiele, wie eine Site dem User behilflich sein kann, oder ihm sogar die Arbeit ganz abnehmen kann.
Naja, Last.fm ist erstmal nur ein super Beispiel dafür, dass man sich ein Musik-Profil anlegen kann, ohne groß was dafür tun zu müssen. (Passt also eigentlich nicht so ganz hier rein, bessere Beispiele folgen;) Man installiert ein kleines Programm und schwupps werden auf Last.fm alle Lieder gesammelt, die man auf dem Rechner hört.
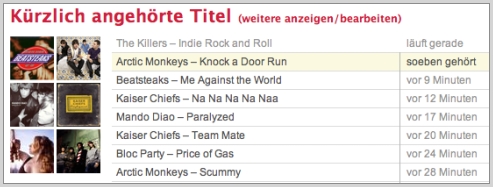
Besseres Beispiel:
Readr.com (via) ist einer der vielen Aggregatoren, die man mit seinen Daten füttern kann, die dann einen sogenannten “Lifestream” erstellen. Dieser Stream zeigt dann chronologisch das, was man auf anderen Websites tut: welche Lieder man via Last.fm hört, welche Websites man auf del.icio.us oder StumbleUpon bookmarkt, welche Bilder man auf Flickr hochlädt etc. Das sieht dann z.B. so aus:

Soweit Readr … worauf ich aber eigentlich hinaus will ist die Art und Weise, wie man bei Readr seine Accounts einträgt (und wie das auch schon einige andere Seiten tun, mir fallen sie nur grad nicht ein). Readr nimmt einem nämlich fast die ganze Arbeit ab, indem er schon mal nach dem bei Readr verwendeten Usernamen und der eMail-Adresse sucht. (Bringt natürlich nur Ergebnisse, wenn man immer unter gleichem Namen auftritt;)
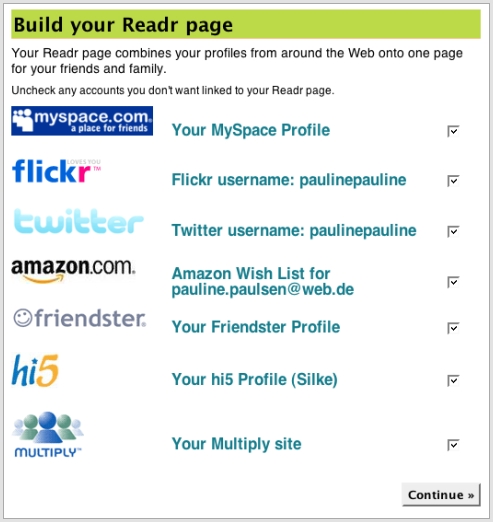
Wenn mal kein Profil gefunden werden konnte, kann man das dann noch händisch nachtragen. In den meisten Fällen geht das auch ganz flott:
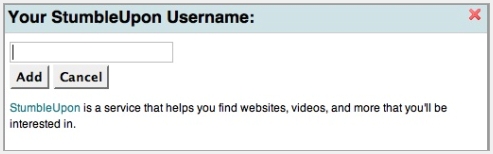
Leider ist es nicht in allen Fälle so einfach … was nicht an Readr sondern an den zu integrierenden Seiten liegt. Diese müssten die Daten leichter zugänglich machen.
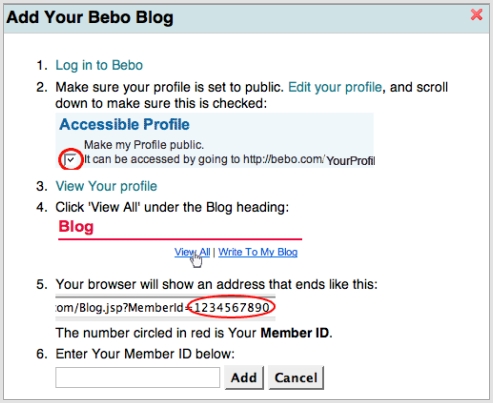
Schönstes Beispiel:
(mal wieder 😉 wer noch ne Einladung braucht, bitte melden)
Bei Dopplr kann man eintragen, wann man wohin reist und dann sehen, welcher der Freunde zur gleichen Zeit dort sein wird. Man kann nun bei Dopplr eine Verknüpfung zum Flickr-Account herstellen um die während dem Trip gemachten Fotos auf der Trip-Seite anzuzeigen. Jetzt könnte man glauben, dass man nun auf Flickr bei den Fotos, die zum entsprechenden Trip gehören, ein Tag setzen muss, damit Dopplr die Zusammenhänge erkennt (so wie das ja auch bei Upcoming läuft). Falsch gedacht 🙂 denn Dopplr ist viel schlauer! Dopplr nutzt die Metadaten der Fotos und sucht sich so die Fotos raus, die während der Tripps gemacht wurden und ordnet sie automatisch zu! (Von diesem Feature habe ich von Stowe Boyd in seinem Web 2.0 Expo-Workshop “Building Social Applications” erfahren.)

Das Ganze hat mich zwei Klicks gekostet: Auf Dopplr auswählen, dass Flickr-Bilder importiert werden sollen und auf Flickr (man wird automatisch dort hingeleitet) die Zustimmung dazu geben. Und so siehts dann auf Dopplr aus:
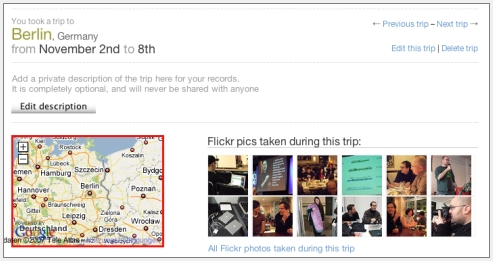
Einmal einstellen und alle Fotos werden immer automatisch den Trips zugeordnet. Perfekt! 🙂
Man muss also nur mal ganz genau überlegen, welche Daten überhaupt vorliegen und die dann geschickt nutzen! Und um diesen Beitrag auch wieder mit Tom Coates Worten abzuschließen:

Und wo kriegt man all diese Daten her? Toms Antwort:

PS @ Holger: Bevor du nun wieder einen Datenschutzanfall kriegst, oder dich fragst, warum die Leute so viel von sich preisgeben … darum gehts hier in meinem Beitrag nicht! 😉
Ich finde solche Automatismen auch immer sehr nett. Die Dienste sollten allerdings auch immer angeben, auf welchem Wege sie Daten bekommen und ein Opt-out anbieten. Machen leider die wenigsten. Dopplr scheint da in die richtige Richtung zu gehen; nutze den Dienst allerdings nicht, um da genauere Aussagen treffen zu können.
Hey,
erstmal vorweg, ein schöner Artikel. Unter dem Motto “Alle Wege führen nach Rom” suchen sich Portale ihre Daten. Beeindruckend, was aus der vielzahl von Daten alles gemacht werden kann.
Ich glaube dem einfachen Nutzer nützt es nichts, wie diese Portale an die Daten kommen, aber sicherlich ist es für Webentwickler schön zusehen, welche Social Communitys, ihre Daten in was für Verfahren anbieten. Bin selber gerade dabei, mich durch die Datenfeeds von LastFM und die Entwicklerschnittstelle von flickr zu arbeiten.
Würde mich übrigends über eine Einladung bei Dopplr freuen. Falls du noch eine zu vergeben hast 😉
Gerade für “einfache Nutzer” sollte das erklärt werden. Im Zweifelsfall kann ich mir noch zusammen reimen, wie Dienst X and die Daten aus Dienst Y gekommen ist. Leute, die sich überhaupt noch nicht mit solchen Fragen beschäftigt haben, dürften hingegen einigermaßen überrascht sein oder sogar meinen, gehackt worden zu sein.
ja, es sollte schon erläutert werden, was da grad passiert. ich war letztens zb. auch einigermaßen überrascht, als ich in einem blog auf einen link in einem widget geklickt hatte, und auf der website des widget-anbieters dann schon meine email-adresse im registrierungsformular eingetragen war. vielleicht wussten die die adresse über ein cookie, denn ich hatte in dem blog schon mal kommentiert und dort meine daten geseichert. es wirkte aber auf alle fälle sehr strange …
und dabei fällt mir auch wieder ein, dass Lijit.com (dieses widget meinte ich gerade eben) auch automatisch die networks nach usernamen und email-adresse scannt, so wie readr.
Danke für den Artikel, so bin ich erst auf readr aufmerksam geworden. Mir ist zwar noch nicht so klar, welchen Nutzen das für mich hat, aber vielleicht erschließt sich der erst, wenn ich auch entsprechend dort vernetzt bin.
ach, solche dienste wie readr gibts ganz viele, aber ich weiß gar nicht mehr, wie die alle heißen … hab den hier nur als beispiel genommen, weil mir die idee zu dem beitrag kam, während ich mich bei readr registrierte (eigentlich nur um das widget auszuprobieren;)